In 2014, a group of researchers looked at 315 quantitative investment strategies from top academic journals. Their conclusion was brutal: most would not survive a basic statistics audit. The paper was called 'Pseudo-Mathematics and Financial Charlatanism.' The problem was not fraud so much as self-deception. Researchers had found patterns in old data that looked like strategies, but were often just noise. So when you see a backtest showing 20% annual returns, do not start with 'are the numbers correct?' Start with: 'do these numbers mean anything?'
What a backtest actually is
A backtest takes a set of rules, applies them to historical data, and asks: what would have happened if you had followed these rules in the past? That is all it is. It is not a forecast. It is a simulation of a history you did not actually live through, built on assumptions about data, timing, costs, and execution.
Those assumptions matter. Before you trust any backtest, including the ones on reblnc.com, you need to know where the numbers can go wrong.
Five ways backtests lie to you
Lie 1: survivorship bias
Suppose you backtest a strategy on 'S&P 500 stocks from 2000 to 2024.' A common mistake is to use today's S&P 500 members, then pretend that list existed back in 2000. It did not. The companies that went bankrupt, were delisted, or got acquired quietly disappear from your test.
That pushes the results upward. Your historical S&P 500 is full of survivors by construction. The backtest gets to know, in advance, which companies would still be around decades later.
Bailey et al. (2014) estimated that survivorship bias can add 1-3 percentage points per year to apparent backtest returns. That is enough to make an average strategy look excellent.
ETF strategies such as GEM and HAA have less of this problem because the strategy trades funds like SPY rather than picking individual stocks. Still, the indexes inside those ETFs have their own constituent histories. Reblnc uses established, liquid ETFs with long histories to reduce this risk, not because the risk magically disappears.
Lie 2: look-ahead bias
Look-ahead bias happens when the backtest uses information that was not available when the trade decision would have been made. Simple examples:
- Using end-of-day closing prices to make decisions that would have required mid-day execution
- Using index membership that was revised later
- Using accounting data that was restated after the original report
In momentum strategies, this often shows up in the lookback calculation. If you calculate GEM's 12-month return on December 31 and assume you traded at the December 31 close, you have a timing problem. You did not know the closing price until after the market closed.
A cleaner setup is to calculate the signal using data available after month-end, then trade at the next open, or apply another realistic delay. That delay usually trims returns by about 0.3-0.8 percentage points per year. Not huge. Not ignorable either.
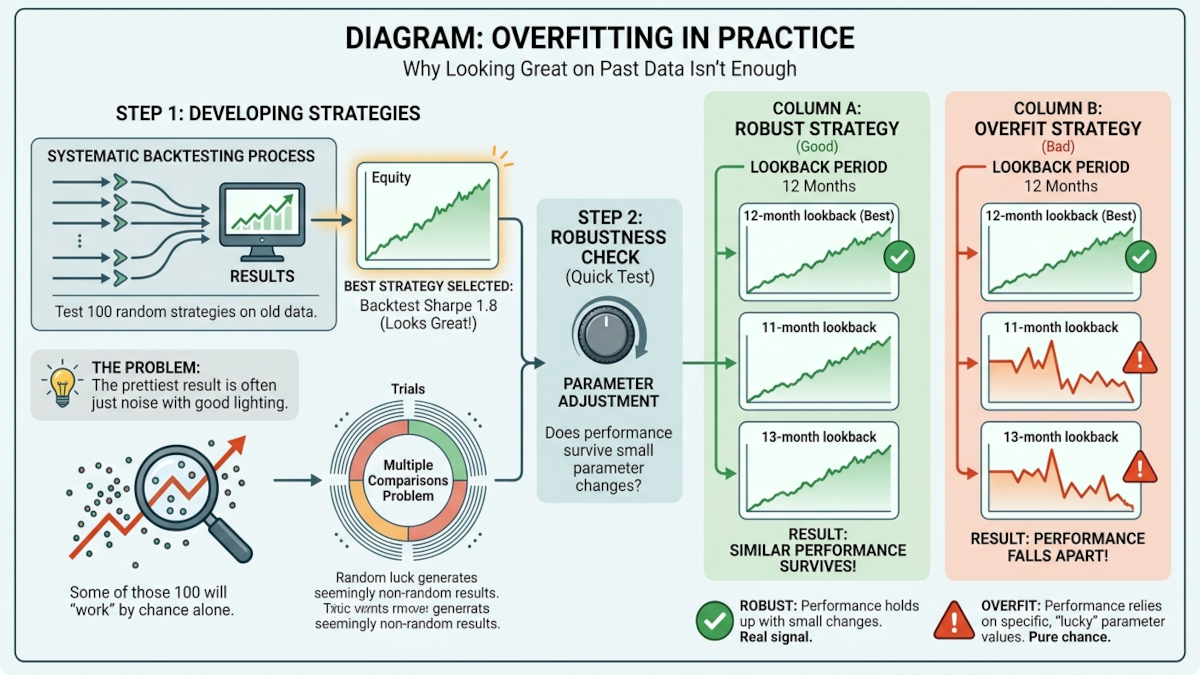
Lie 3: overfitting
Overfitting is the one to fear. It happens when you test a pile of parameter combinations and publish the one that worked best, without admitting that you searched until the historical noise gave you something pretty.
Harvey, Liu, and Zhu (2016) argued that after you account for multiple testing, a strategy needs very strong statistical evidence, roughly a t-statistic above 3.0, before you should take it seriously. Most published strategies do not clear that bar.
Imagine testing 100 moving-average strategies on S&P 500 data and reporting only the one with the best Sharpe ratio. Of course one will look good. That does not mean you found a real edge. Even 100 coin-flip strategies will produce a few impressive-looking winners by chance.
"A researcher who tests 100 strategies and reports the best one has essentially created a strategy with no predictive value, regardless of how good the backtest looks." — Harvey, Liu, and Zhu (2016)
GEM's 12-month lookback is stronger than that because it came from prior academic work rather than a search across every possible lookback window. Strategies with dozens of knobs, such as lookbacks, filters, universe sizes, and thresholds, are much easier to overfit.
Lie 4: underestimated trading costs
Many academic backtests assume no trading costs, or costs so low they might as well be decorative. Real ETF trading has three main frictions:
- Bid-ask spread: the gap between the price you can buy at and the price you can sell at. For liquid ETFs such as SPY this is tiny, often 0.01-0.02%. For less liquid international ETFs it can be 0.1-0.3%.
- Market impact: large orders move prices against you. Retail investors trading one or two ETFs usually do not care. Institutions do.
- Tax drag: in taxable accounts, each rebalance can create taxable gains. Depending on your tax rate and holding period, this can remove 1-2 percentage points per year.
For GEM, this is manageable. It checks monthly, but it does not trade every month. In practice it often creates only one or two trades per year. Daily strategies, or strategies with large universes, can bleed far more through costs.
Lie 5: cherry-picked regimes
Every backtest covers a particular slice of history. Pick the slice carefully enough and almost anything can look clever. A 1995-2015 test flatters US equity strategies because it captures the late-1990s boom and the post-2009 bull market. A 2000-2012 test flatters strategies that avoided crashes.
Marcos Lopez de Prado (2018) proposed the deflated Sharpe ratio to deal with this problem. It adjusts for things like how many strategy variants were tested and how long the backtest was. The point is simple: a good-looking Sharpe ratio is less impressive if you tried many versions before finding it.
As a reader, check more than one time period. A strategy that looks brilliant from 1990-2026 but poor from 2014-2026 deserves suspicion. I would rather see moderate, consistent performance than one heroic chart built on one lucky era.
How to read reblnc backtest data
Reblnc shows several metrics for each strategy. The useful part is knowing what each metric can and cannot tell you.
CAGR
CAGR is the annualized return. It is the number everyone notices first, which is exactly why it can mislead you. A strategy with 15% CAGR and a 60% max drawdown is not automatically better than one with 12% CAGR and a 15% drawdown. The second strategy may be the only one you would actually hold.
Max drawdown
Max drawdown is the largest peak-to-trough loss in the tested period. It may be more important than CAGR because it asks a brutal question: would you still be there? Plenty of investors who lived through 2008-2009 sold near the bottom. A strategy you abandon is worth less than a lower-return strategy you can actually stick with.
Sharpe ratio
Sharpe ratio measures return per unit of volatility, using the risk-free rate as the baseline. Above 0.5 is decent. Above 1.0 is strong for a diversified portfolio. The catch: Sharpe treats upside and downside volatility the same. For momentum strategies, Sortino can be more useful because it focuses on downside volatility.
Out-of-sample period
This is the first thing I would check: when was the strategy published, and how has it done since? GEM was published in 2012, so it now has more than 12 years of out-of-sample history. HAA was published in 2022. The shorter the out-of-sample period, the more humility you need.
The strongest evidence: publication plus out-of-sample history
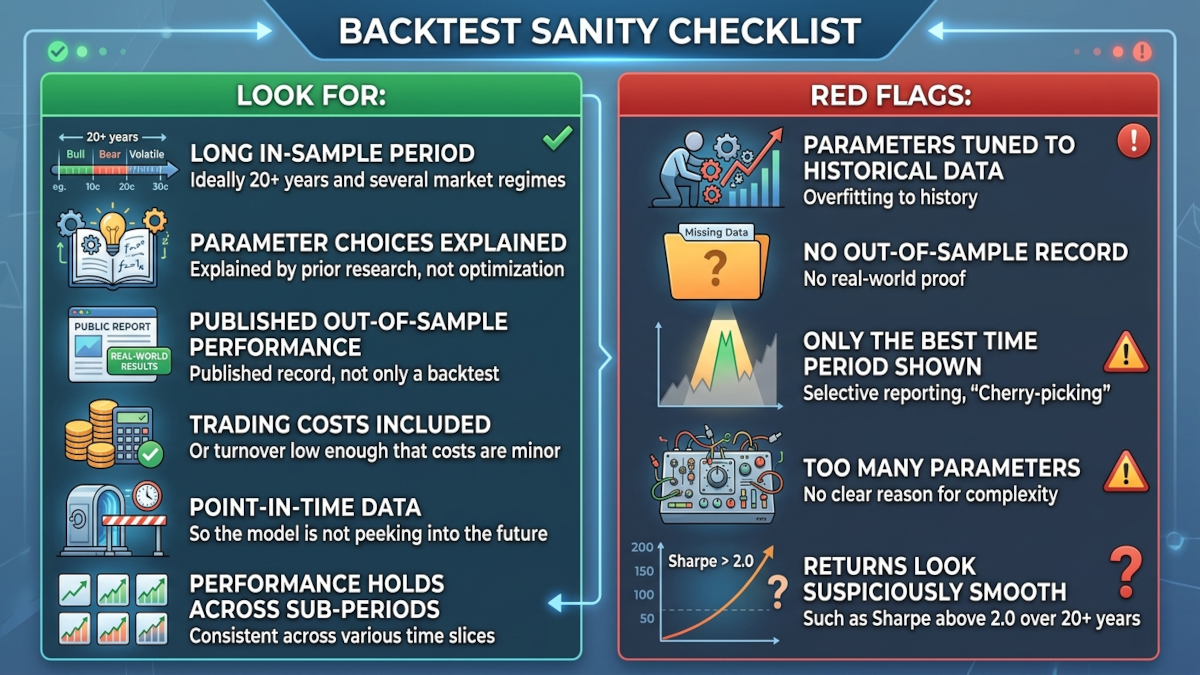
For a momentum strategy, the best evidence usually has four parts:
- It was published in a peer-reviewed journal, so the method faced at least some scrutiny.
- Its parameters come from prior research rather than a search for the best historical result.
- Independently tracked out-of-sample by a third party (like Allocate Smartly)
- Its out-of-sample performance is roughly consistent with the backtest, usually a bit weaker.
GEM meets those four tests. It was published academically, uses parameters grounded in prior research, has been tracked since 2012, and its live performance is weaker than the 1974-2013 backtest but still broadly in line with what you would expect after a strategy becomes public.
HAA and DAA meet the first three tests. The fourth is still building because they have shorter live records.
What this means when choosing a strategy
When you compare strategies on reblnc, do not stop at the headline CAGR.
- Compare strategies over the same dates. A strategy can look better simply because it started in a friendlier period.
- Prefer steady performance across sub-periods over one spectacular era.
- Take drawdowns seriously. A 30% loss in a chart is trivia. A 30% loss in your account is a different animal.
- Look at out-of-sample performance, not only the full backtest.
Reblnc backtests are built to reduce look-ahead and survivorship bias by using established ETFs and consistent historical data. Still, no backtest is clean enough to deserve blind trust. Treat it as evidence, not a promise.
Key takeaways
- Survivorship bias can inflate returns by leaving out assets that failed. ETF strategies reduce this risk, but they do not remove it entirely.
- Look-ahead bias appears when the signal uses data that was not available at decision time. Execution delay matters.
- Overfitting is the most dangerous trap. If you test enough parameter combinations, something will look brilliant by accident.
- GEM's 12-month lookback is more credible because it came from prior academic literature rather than a search over historical data.
- Trading costs and taxes are often understated, especially for high-turnover strategies.
- Always check out-of-sample performance: when was the strategy published, and what happened after that?
- The best evidence is academic publication, parameters grounded in research, independent tracking, and live performance that broadly matches the backtest.
Sources and further reading
- Bailey, D.H., Borwein, J., Lopez de Prado, M., & Zhu, Q.J. (2014). 'Pseudo-Mathematics and Financial Charlatanism: The Effects of Backtest Overfitting on Out-of-Sample Performance.' Notices of the AMS, 61(5), 458–471.
- Harvey, C.R., Liu, Y., & Zhu, H. (2016). '…and the Cross-Section of Expected Returns.' Review of Financial Studies, 29(1), 5–68.
- Lopez de Prado, M. (2018). Advances in Financial Machine Learning. Wiley. (Chapters 11–12 on backtesting methodology)
- Jegadeesh, N., & Titman, S. (2001). 'Profitability of Momentum Strategies: An Evaluation of Alternative Explanations.' Journal of Finance, 56(2), 699–720.
- Fama, E.F. (1991). 'Efficient Capital Markets: II.' Journal of Finance, 46(5), 1575–1617.
- Antonacci, G. (2014). Dual Momentum Investing. McGraw-Hill Education. (Chapter 6 on backtest methodology)
Subscribe to our research
Get the latest tactical allocation strategies and academic whitepapers delivered to your inbox.